APPLICAZIONI INFORMATICHE
ESPERIENZE (E PROBLEMI) DI UN ITALIANISTA
(intervento al seminario "Un'altra rete a mezzo del mio corso": progetti (e problemi) dell'italianistica in rete, tenuto 26 ottobre 2001 presso la Facoltà di Scienze della Formazione dell'Università di Torino per iniziativa di Mario Pozzi [se ne può vedere la locandina])
{kind=link}
Non ho nessuna propensione per i dibattiti teorici. Non vi parlerò, dunque, del futuro della comunicazione né di come gli ipertesti salveranno il mondo. Cercherò di fare un discorso concreto su esperienze concrete e su problemi vissuti.
Le esperienze e i problemi che conosco meglio sono i miei. Parlerò, dunque, di questi.
Nei giorni passati ho riflettuto su ciò. Anzi, ho riflettuto troppo: se dovessi esporre tutto abuserei della vostra pazienza. Mi limiterò a dire qualcosa dell'esperienza centrale della mia 'carriera' di italianista informatizzato (anzi io preferisco dire semplicemente informato), cioè della Banca Dati Telematica "Nuovo Rinascimento" [http://www.nuovorinascimento.org].
"Nuovo Rinascimento" è stato fondato nel 1995. Per inquadrare l'era geologica basterà ricordare che il protocollo HTTP (sul quale si basa Internet) risale al 1989-90; nel 1992 è stato divulgato il primo browser grafico WWW, Mosaic dell'NCSA; al 1993 risale la prima release di Netscape; soltanto nel 1995 compare Internet Explorer.
"Nuovo Rinascimento" è improntato a una filosofia 'minimalista'. Si fonda su un'informatica 'povera' e mira alla semplicità, all'abolizione del superfluo. Cioè si propone di ridurre i costi (economici ed umani), i tempi (di progettazione e realizzazione), il carico (su server e client). Punta dunque sulla velocità di connessione e di download (la homepage è tuttora di 5 Kb e non contiene immagini), alla portata di tutti, anche di chi non può permettersi i mostruosi PC che il mercato ci impone. E semplicità vuol dire anche facilità di comprensione, alla portata di tutti, anche di chi ha un'esperienza informatica limitata.
La struttura della banca dati è abbastanza antiquata (ma ancora funzionale). È una struttura "ad albero", simile a quella dei vecchi Gopher o a quella che appare a chi utilizza un file manager.
Eccone lo schema semplificato:
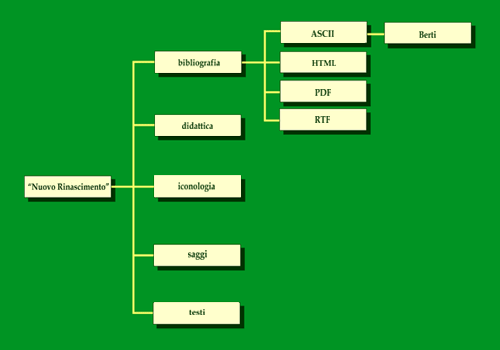
Dalla directory radice si diramano tante directory quante sono le categorie di oggetti che costituiscono la banca dati (per esempio BIBLIOGRAFIA, DIDATTICA, ICONOGRAFIA, SAGGI, TESTI ecc.). Le directory tematiche contengono tante subdirectory quanti sono i formati dei file in esse contenuti (ASCII, HTML, PDF, RTF, WWord). Dalle subdirectory partono altre subdirectory che identificano gli autori del materiale in esse contenuti. Soltanto a questo punto si incontrano i documenti veri e propri.
In questo modo l'indice costituisce una sitemap completa.
La struttura del sito è un ipertesto HTML 'puro' che ha una funzione esclusivamente comunicativa (da 'cinghia di trasmissione'). Il contenuto è in gran parte costituito da file di testo. Questo spiega l'assenza di un motore di ricerca (per il quale una gran parte del contenuto resterebbe invisibile). Sono invece presenti indici analitici (Indice degli autori, Indice dei curatori, Indice dei soggetti, Indice dei titoli), del tutto simili a quelli che corredano le edizioni cartacee, che offrono l'utilità di una visualizzazione ordinata del contenuto (una overview da varie angolazioni).
In origine i documenti erano in formato ASCII (il codice universale di corrispondenza tra segni alfanumerici e sistema binario) [estensione: txt]. Allora l'imperativo categorico era che tutti devono essere in grado di leggere i testi, qualunque sia la piattaforma che si utilizza. Ma in ogni caso si trattava di un ASCII esteso (non di 128 ma di 256 caratteri, per coprire le lettere accentate) Può esserne un esempio la Marfisa di Pietro Aretino [vedi].
Ma fin dall'inizio fu chiaro che lo standard ASCII al massimo può andar bene per i più semplici testi poetici: per la saggistica è indispensabile una formattazione evoluta. Si passò dunque a documenti elaborati con Microsoft Word [estensione: doc], indicando a chi non possiede il programma la possibilità di utilizzare WordViewer, distribuito dalla Microsoft come freeware. Può esserne un esempio il saggio Il "pro bono malum" ariostesco e la Bibbia di Alberto Casadei [vedi].
Per aggirare il problema dei modelli di documento utilizzati da Word (che possono variare da utente a utente e determinare una visualizzazione imperfetta) si è fatto largo uso del Rich Text Format [estensione: rtf]: standard multipiattaforma che definisce la formattazione senza ricorrere a modelli esterni al documento. Può esserne un esempio il saggio Per la memoria leopardiana di Rebora di Simone Magherini [vedi].
Infine si è optato, nella maggioranza dei casi, per il formato Acrobat della Adobe [estensione: pdf], che utilizza per la visualizzazione un freeware (Acrobat Reader) e salvaguarda quasi in tutto l'impaginazione scelta dall'autore. Possono esserne un esempio Gli esercizi emendati di Michelangelo Buonarroti il Giovane curati da Luca Battisti [vedi].
Non mancano gli ipertesti HTML (come Un trecentesco florilegio iconico della "Commedia" di Massimiliano Chiamenti) [vedi] né realizzazioni interamente grafiche (con supporto HTML), come quella di un rarissimo libretto di Niccolò Tommaseo, Versi facili per la gente difficile (riproduzione della stampa litografica del 1837), a cura e con introduzione di Jacopo Berti, del quale esiste un solo esemplare nelle biblioteche pubbliche italiane [vedi].
Nel 1998 si sono affiancate a "Nuovo Rinascimento" due banche dati satelliti: "Pagine di Maura Del Serra" [vedi], tentativo di cooperazione con una scrittrice vivente, poetessa, drammaurga, saggista, traduttrice [se ne può vedere l'Antologia poetica]; e la "Banca Dati 'Giulio Rospigliosi'": un vero ipertesto, questa volta, multicentrico e multimediale, costituito da documenti di varia natura e in vario formato (naturalmente in progress), dedicato al papa (Clemente IX) che fu uno dei maggiori uomini di teatro del Seicento [vedi].
Non vorrei far credere che la mia 'carriera' di italianista informato (peraltro non limitata a "Nuovo Rinascimento") sia una 'carriera' tutta in positivo, di conquista in conquista e di successo in successo. Non sono mancati i problemi, le delusioni e i fallimenti.
Un fallimento si è rivelata la Bibliografia 'aperta' dei classici italiani in rete (in forma di ipertesto HTML) [vedi], immessa in "Nuovo Rinascimento" il 23 luglio 1996 e mai più aggiornata. Non si trattava di uno dei soliti indici di risorse, ma di una vera e propria bigliografia che cercava di applicare al materiale on line i criteri di scientificità e di completezza che si richiedono a un lavoro bibliografico serio, adattandoli alla natura non tradizionale del contenuto e del contenitore.
Ben presto si è capito che l'impresa era ingestibile: non poteva essere opera di un singolo ricercatore. Il monitoraggio coordinato e sistematico di un oggetto in continuo movimento come Internet non può che essere affidato a un team.
A questo punto ho avuto un sussulto d'orgoglio. Mi sono detto: se si deve creare un gruppo di lavoro strutturato, perché limitarsi alla letteratura in rete? Perché non estendere il monitoraggio a tutta la letteratura? Perché non creare una bibliografia corrente on line della letteratura italiana? Perché aspettare due o tre anni che escano le (costosissime) bibliografie su carta (come il LIAB e la BiGLLI)? Si può avere una bibliografia aggiornata 'in tempo reale' che non costa nulla all'utente (tranne il costo della connessione).
Giocano a favore dell'ipotesi l'abbattimento dei costi di gestione e la possibilità di una sorta di 'autoaggiornamento'. È interesse del produttore far conoscere il suo prodotto: gli autori stessi possono segnalare le loro pubblicazioni mediante form o e-mail, si possono stipulare convenzioni con gli editori, ai quali si fornisce pubblicità gratuita (a parte il fatto che quasi tutti hanno già il catalogo on line, che si può utilizzare), si può avviare qualche forma di collaborazione con Enti, Istituzioni, Università ecc. (anche straniere), si possono concepire forme di partnership con altri soggetti (italiani e stranieri) che possono partecipare a pieno titolo all'impresa, ecc. ecc.
Nacque così il progetto della Bibliografia Telematica della Letteratura Italiana (BiTLI), che avrebbe dovuto girare su un server SQL con un'interfeccia ipertestuale.
Fu chiesto un finanziamento di 50 milioni (il contributo minimo prescritto) come progetto "strategico" 1996.
Ebbene, il progetto non solo non fu finanziato, ma non fu neanche ammesso alla pubblica presentazione. Cioè la facoltà alla quale appartengo ritenne che si trattasse di impresa così scervellata da non meritare neppure che se ne parlasse in pubblico.
Voglio concludere questo mio intervento con un altro progetto rimasto allo stato di abbozzo, questa volta per ragioni squisitamente tecniche: un problema rimasto irrisolto.
Il progetto consiste nell'Edizione critica ipertestuale dei "Ricordi" di Francesco Guicciardini.
In verità si tratta di un testo che non soffre di particolare incuria filologica. Anzi, l'edizione critica di Raffele Spongano (Francesco Guicciardini, Ricordi, edizione critica a cura di Raffaele Spongano, Firenze, G. C. Sansoni Editore, mcmli) è considerata uno dei classici della nostra filologia. Nauralmente tutto invecchia, ma direi che l'edizione Spongano ancora si difende bene.
Allora perché farne una nuova edizione e perché farne un'edizione ipertestuale?
Per chiarire la problematica implicata devo fare una brevissima sintesi della storia redazionale del testo.
Semplificando al massimo si può dire che dei Ricordi ci sono pervenute cinque redazioni d'autore, così individuate da Spongano:
Q1 - autografo (13 ricordi) [1512]
Q2 - autografo (29 ricordi) [1512]
A - apografo (161 ricordi) [ante 1525]
B - autografo (181 ricordi) [1528]
C - autografo (225 ricordi) [1530]
L'edizione Spongano si configura secondo lo schema rappresentato da questa figura:
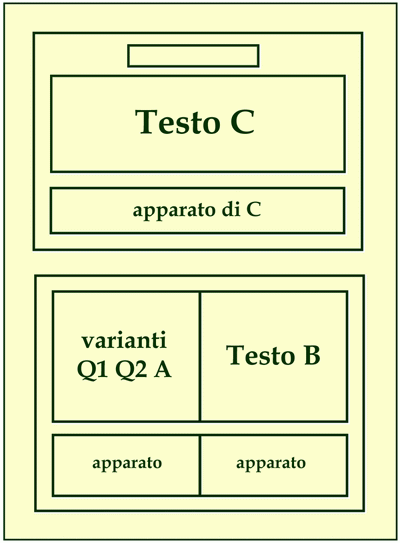
La pagina è divisa in due parti. Nella parte superiore si riporta l'"ultima volontà" dell'autore (C) con il suo apparato (ed è il testo C a determinare l'ordinamento dei ricordi). La parte inferiore si divide a sua volta in due parti. La parte di destra riporta il testo B con il suo apparato. La parte di sinistra accoglie le varianti di Q1, Q2 e A con relativo apparato. Qualora le divergenze rispetto a C siano tali da non poter essere rappresentate con un sistema di varianti, se ne riporta il testo per intero. I ricordi di Q1, Q2, A e B che non trovano riscontro in C sono trascritti in appendice.
In conseguenza di questa strategia ecdotica l'edizione Spongano presenta dei seri inconvenienti:
- è impossibile leggere nella sua integrità il testo della maggior parte dei ricordi delle redazioni Q1, Q2 e A
- è impossibile leggere le redazioni Q1, Q2, A e B nella loro completezza secondo l'ordinamento voluto di volta in volta dall'autore (ed è superfluo dire che in un'opera di questo peso la struttura 'grafica' ha rilievo di struttura logica)
- è impossibile seguire lo sviluppo redazionale dei singoli ricordi secondo la sua direzione naturale (procedendo dal prima al dopo: bisogna invece procedere a ritroso): l'egemonia dell'"ultima volontà" sacrifica (o almeno appiattisce) la storia del testo
- è impossibile leggere le redazioni Q1, Q2, A e B nella loro completezza secondo l'ordinamento voluto di volta in volta dall'autore (ed è superfluo dire che in un'opera di questo peso la struttura 'grafica' ha rilievo di struttura logica)
Si può ovviare a questi limiti, propri di un'edizione critica cartacea, con stumenti informatici?
Si prospettano varie possibilità. Qui ne indichiamo due:
- esistono browser studiati specificamente per 'navigare' tra le varianti testali; per esempio il Digital Variants Project offre uno strumento assai raffinato a questo fine
- si può fare ricorso a un motore ipertestuale (favorito dalla struttura modulare del testo), sviluppando un sistema di link che 'cuciono' fra loro le varianti.
A mio parere entrambe queste soluzioni presentano un grosso problema di comunicazione. Per 'pubblicare' un'edizione elettronica così concepita si deve realizzare un CD ROM che contiene il prodotto ecdotico e un programma per farlo funzionare. Questo comporta costi notevoli di produzione, di royalties, di distribuzione ecc. Inoltre si devono fare i conti con il rapido invecchiamento del software. Basta ricordare che la prima edizione della LIZ (Letteratura Italiana Zanichelli), realizzata in Microsoft DOS e pubblicata nel 1995 è già inservibile: con i nuovi sistemi operativi non si riesce neppure a installare il programma. Lo stesso vale per l'unica edizione critica elettronica di un'opera letteraria italiana che finora sia stata realizzata, La bottega dell'antiquario di Carlo Goldoni a cura di Luca Toschi, pubblicata da Marsilio nel 1996.
Questi problemi potrebbero essere automaticamente superati adottando un ipertesto HTML pubblicato in Internet, che non presenta di per sé spese vive per l'editore ed è a costo zero per l'utente, si serve di un linguaggio 'universale' e di un canale di comunicazione 'universale', può essere sistematicamente aggiornato (compresa la migrazione a XML qualora si rendesse necessaria), presenta possibilità di espansione pressoché infinite (restando un work in progress perenne). È vero, peraltro, che l'HTML è meno efficiente dei migliori prodotti proprietari che sono in commercio.
Alla luce di queste considerazioni qualche anno fa ho concepito il progetto di un'edizione dei Ricordi in HTML da destinare a Internet. L'opera non è mai stata portata a compimento; è rimasta un'ipotesi di lavoro. Ho realizzato un modello (funzionante, ma ancora da rifinire) che comprende soltanto una piccola parte del testo e delle sue varianti: una specie di 'demo giocabile' reperibile in "Nuovo Rinascimento" [vedi]. La grafica – è superfluo dirlo – è abbastanza rudimentale.
Ecco come funziona.
Sulla parte sinistra dello schermo compare un Indice (provvisorio) che immette in una qualsiasi delle redazioni (a scelta dell'utente). Soltanto la redazione Q1 è completa, delle altre compaiono soltanto i primi dieci ricordi con i relativi 'corrispondenti' nelle altre redazioni. Ogni ricordo costituisce un documento, strutturato come una tabella, con varie celle e altre tabelle in esse annidate.
In calce vi sono due serie di pulsanti. La prima serie consente di navigare all'interno della redazione in cui ci troviamo. La seconda serie consente di navigare tra una redazione e l'altra, passando automaticamente dal ricordo aperto nella cella principale ai ricordi che corrispondono ad esso nelle altre redazioni del testo (ammesso che vi siano). I pulsanti attivi risultano contornati da una casella di colore bianco. Quando appare più di un pulsante con la stessa sigla significa che il ricordo aperto nella finestra principale trova più di un 'corrispondente' nella redazione indicata dalla sigla stessa.
Non esiste, ma è previsto un motore di ricerca, se non full text almeno per parole-chiave.
Si possono prevedere anche ulteriori sviluppi. Per esempio una terza serie di pulsanti che consentano di accedere a un'immagine del manoscritto, a un apparato, a un commento, a un glossario, a percorsi tematici ecc.
In realtà l'impresa è ferma da anni. Naturalmente nel frattempo sono sopravvenuti altri impegni più urgenti, ma la causa principale dell'interruzione del lavoro è costituita da una non lieve perplessità che investe l'architettura stessa del progetto.
Queste sono le considerazioni che generano dubbio.
Anzitutto l'insieme – una volta che sia realizzato nella sua interezza – è abbastanza macchinoso. Infatti la sola 'demo giocabile' è costituita da 135 file e da almeno un migliaio di link. A regime si possono prevedere ben oltre 500 file (se non si prendono in considerazione sviluppi significativi) per decine di migliaia di link.
Ma ne vale la pena?
Se è vero ciò che funziona, il progetto funziona, quindi è vero (cioè valido), anche se la tecnologia è un po' antiquata.
Però è economico? Cioè: si può immaginare un'altra macchina che funzioni altrettanto bene (o anche meglio) e 'costi' meno?
Forse sì.
Per esempio si può immaginare non un ipertesto (modulare, composto da centinaia o migliaia di documenti collegati tra loro), ma un solo grande documento, una specie di macrotesto, generato anche con Word (cosa che semplifica di molto le operazioni), che contenga tutte le redazioni complete, con le relative concordanze. Questo macrotesto potrebbe essere convertito in formato PDF con Adobe Acrobat e quindi assumere tutte le funzioni di Acrobat Reader: segnalibri, link ipertestuali, possibilità di disporre di una overview, possibilità di aprire più finestre, soluzioni grafiche raffinate ecc.). Il software di lettura è un freeware e il macrotesto potrebbe essere distribuito on line con la massima semplicità.
Il prodotto conterrebbe la stessa quantità di informazione, forse perderebbe qualcosa in funzionalità, forse comporterebbe un funzionamento meno intuitivo, forse sarebbe meno 'decorativo' di un ipertesto. Certamente sarebbe più semplice dal punto di vista della realizzazione e per questo sarebbe più economico. Certamente sarebbe più complicato da gestire a causa delle dimensioni del file e per questo sarebbe meno economico.
L'alternativa resta irrisolta. Ed esistono - beninteso - altre soluzioni.